Supporting information and data for the paper "Mixing hetero- and homogeneous models in weighted ensembles"
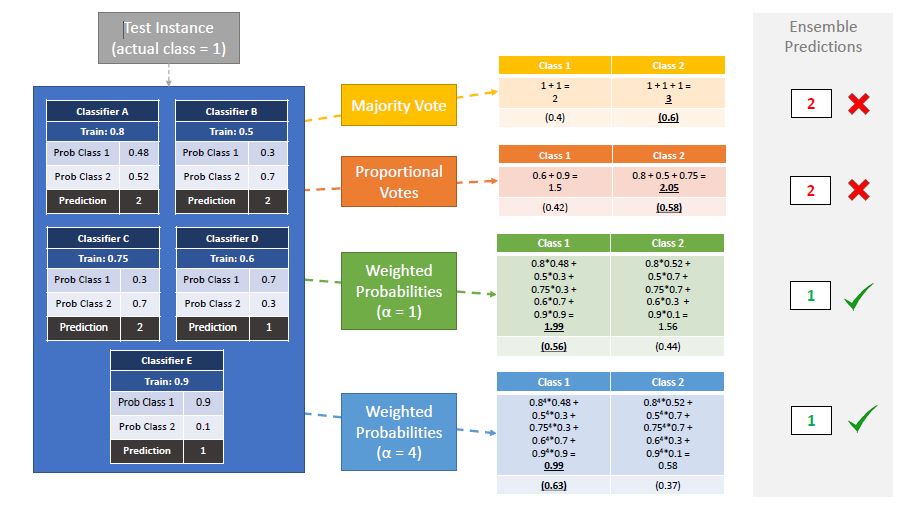
The effectiveness of ensembling for improving classification performance is well documented. Broadly speaking, ensemble design can be expressed as a spectrum where at one end a set of heterogeneous classifiers model the same data, and at the other homogeneous models derived from the same classification algorithm are diversified through data manipulation. The cross-validation accuracy weighted probabilistic ensemble is a heterogeneous weighted ensemble scheme that needs reliable estimates of error from its base classifiers. It estimates error through a cross-validation process, and raises the estimates to a power to accentuate differences. We study the effects of maintaining all models trained during cross-validation on the final ensemble's predictive performance, and the base model's and resulting ensembles' variance and robustness across datasets and resamples. We find that augmenting the ensemble through the retention of all models trained provides a consistent and significant improvement, despite reductions in the reliability of the base models' performance estimates.
The full, up to date codebase can be found here, however a stable branch at the time of final submission with accompanying summary results can be found here
Generating data resamples is deterministic and can be reproduced using the method (Experiments.sampleDataset(directory,datasetName,foldID), using the UCI data or alternatively all folds can be downloaded (3.5 GB).
In the course of experiments we have generated gigabytes of prediction information and results. These are available as spreadsheets and figures and could also be sent out in raw format (2.7 GB), ask james.large@uea.ac.uk.