Alan Turing Institute Time Series Machine Learning/Artificial Intelligence Toolbox
The GitHub page is here
sktime is an Alan Turing Institute project to develop a unified platform for time series tasks in Python. Our goal is to bring together a range of algorithms developed in the fields of statistics and data mining within a simple to use framework that facilitates rapid exploratory analysis of a range of techniques, easy development of new algorithms and the rigorous assessment and benchmarking against the state of the art. Our three initial use cases are classification, forecasting and panel forecasting.
Time Series Classification
Our current TSC toolkit, implemented in Java and integrated with Weka, (TSC Toolkit), primarily focusses on univariate TSC of series with equal length. Our goal for sklearn is to port over some of the algorithms into Python, testing for correctness and efficiency against the Java versions as we go, then extending the classifiers to handle more varied use-cases, to include univariate and multivariate time series classification with potentially missing values and unequal length series. Our first goal is to port over the components of HIVE-COTE. Once complete and benchmarked, we will expand the algorithm base to include more recently proposed techniques such as Proximity Forest, WEASEL and alternative deep learning approaches. Our initial benchmarking is performed using the same 85 data sets used in the bakeoff (a comparison of algorithms described here . This is really just for sanity checking to make sure we can reproduce our own results in Java four years and many changes after we started the process, and to blackbox debug our Python implementations. We are also particularly concerned about run time in python. Once the code has stabilised we will conduct a full comparison on the new univariate and multivariate archives. The webpage is a work in progress, and will contain some comments in note format.
Time Series Forest (TSF) algorithm details
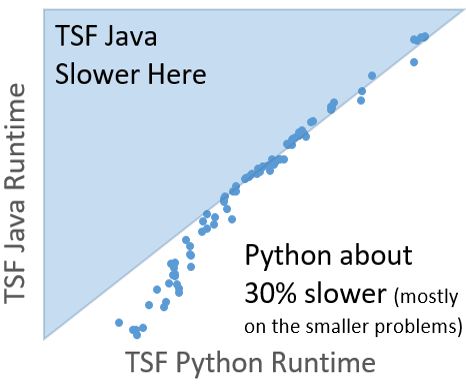
TSF is the simplest of the components in HIVE-COTE and hence a sensible starting point. It is also a good testbed for demonstrating the efficiency issues that we encounter in Python. Each ensemble member is defined by a set of random intervals on the series. Summary info (mean, sd and slope) is calculated on each interval, and these stats are concatenated to form a new feature set for each ensemble member. The base classifier is a decision tree. In Java we use RandomTree, in Python the sklearn the DecisionTreeClassifier using information gain.
|
|
|---|
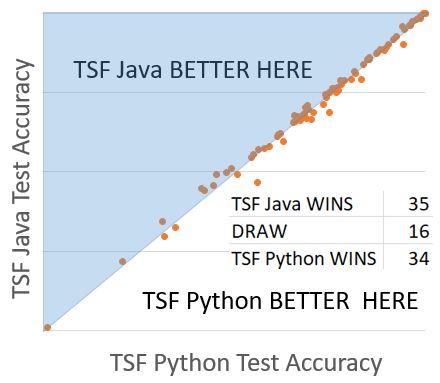
These implementations are equivalent in accuracy and timing. It is worth noting that these results are obtained with a Python implementation based purely on numpy arrays that is not configurable. Using a more general purpose TSF implementation significantly slows it down.
Bag of SFA Symbols (BOSS) algorithm details
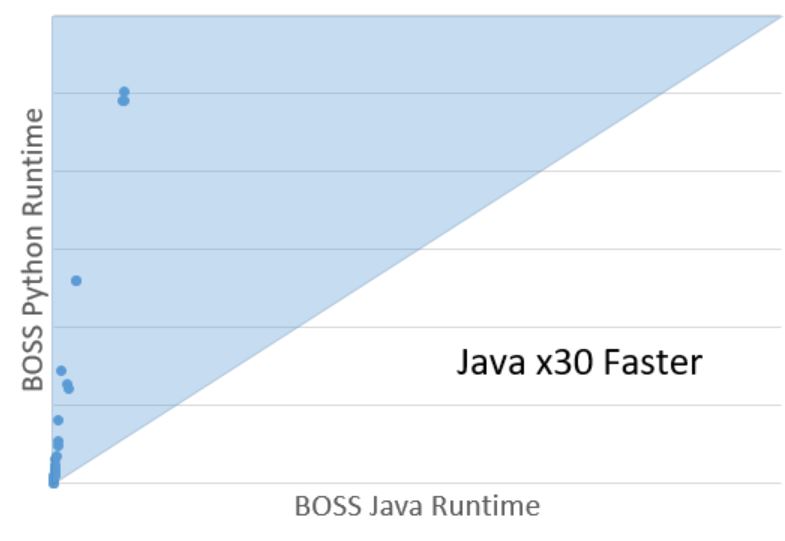
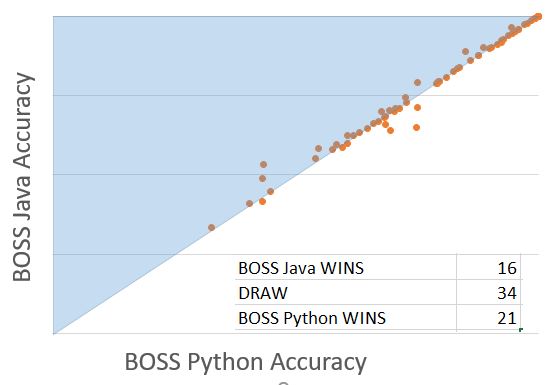
BOSS is a dictionary based classifier that ensembles over different parameter settings. Briefly, a sliding window is passed over a series, which is truncated using a fixed number of Fourier coefficients and discretised to form a word. A histogram of word counts is formed, and classification occurs with a nearest neighbour classifier with a bespoke distance measure. Our Python BOSS was implemented Python with little optimization. Our first objective is correctness. The accuracies we obtain with Python BOSS are not significantly different to the Java implementation. However, python is 30 times slower. Our next task with this module is to reduce that difference.
|
|
|---|
Random Interval Spectral Ensemble (RISE) algorithm details
RISE operates similarly to TSF, with this difference. It randomly chooses a single interval for each base classifier, then finds the autocorrelation function, partial autocorrelation function and power spectrum, and uses these as features for the classifier. It uses the same base classifiers as TSF.
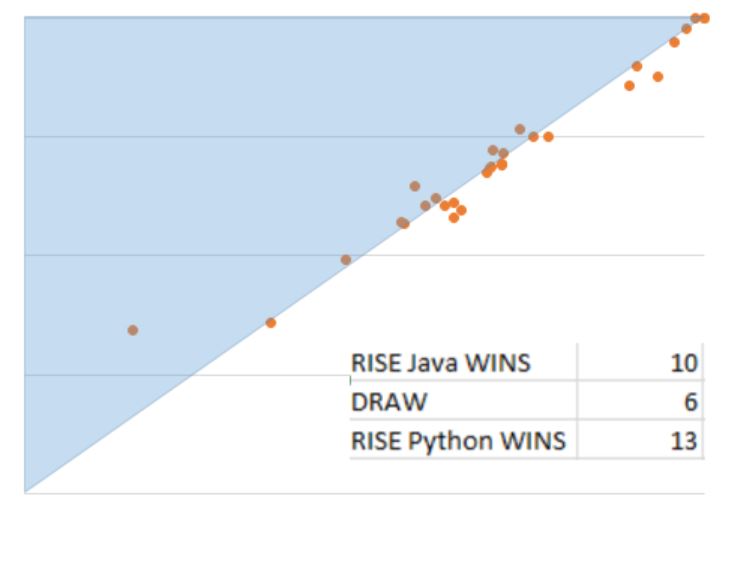
Elastic Ensemble (EE) details
The elastic ensemble is an ensemble of nearest neighbour classifiers using a range of warping/editing based distance measures. The nature of the calculations involved mean the native python version is incredibly slow. Thus we are wrapping it all in cython. CURRENT RESULTS ON DTW, DDTW and WDTW to follow
Shapelet Transform Ensemble (ST) algorithm details
The shapelet transform finds a set of discriminatory phase independent shapelets, then transforms the problem into attributes representing distance to shapelet. RESULTS TO FOLLOWCurrently we always use a contract version for shapelets, where it randomly samples shapelets until the time limit is reached. Timing comparisons will need to be done in a more low level way.